年底了虽然有各种告警,不过还是需要做一下全网巡检,这里以磁盘使用率为例。由于目前平台上使用的是商业版的自动化工具bmc,其在执行分发都方面非常不存,不过在取值返回上做的不好---当然也和其是商业化工具有关,很多东西不开源,用shell 的语法概念写nsh时又执行不通过,nnd总是要问原厂支撑 。刚好在测试环境上有之前安装的ansible环境,也测试下用ansible 来实现该功能。
一、实现目标将所有主机的磁盘大于75%的主机获取到,并输出为下面的格式:
主机IP 主机名 磁盘挂载点信息 磁盘使用率
假如 host1上有多个分区都大于75% ,则写多条。当主机上没有一台符合时,则什么都不输出。
注:现网主机上有两个 bond 网卡,其中一个配置的是10段的IP,另一个配置的是192段的IP。这里要获取的是10段的IP。
二、 ansible + awk 简单输出该问题我处理的结果是使用ansible api 写的一个python脚本实现的。先看下我在一个技术群和一个大牛的讨论的结果。
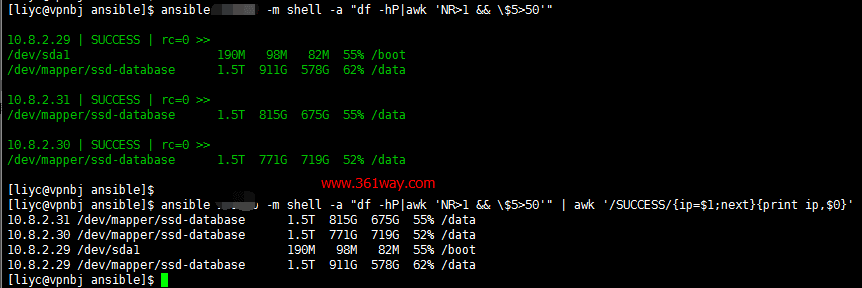
如上图,大牛的做法用的是awk 的next方法进行的处理,awk 的next功能我也做过记录,具体参看awk next多行合并 。
这里有几个注意点需要说明下:
[root@361way ~]# df -hP|awk 'NR>1 && $5 > 20' /dev/xvda1 20G 4.6G 15G 25% / /dev/xvdb 20G 645M 18G 4% /data1 [root@361way ~]# df -hP|awk 'NR>1 && int($5) > 20' /dev/xvda1 20G 4.6G 15G 25% /
有没有看到,如果不做int格式转换取的结果是所有分区的信息,而加上int后获取的才是我们想要的结果
# ansible all -m shell -a "df -hP|awk 'NR>1 && int($5) > 50'" 10.212.52.252 | FAILED | rc=2 >> awk: fatal: 0 is invalid as number of arguments for int [root@361way ~]# df -hP|awk 'NR>1 && int(\$5) > 20' awk: NR>1 && int(\$5) > 20 awk: ^ backslash not last character on line
如上面的结果,如果在ansible执行时不加转义时会有报错提示,如果加上转义在主机端执行时会自动是将转义符去掉的结果。而在主机端执行时,如果加上了转义也会报错。所以主机端一定不能加上转义。
[root@localhost ~]# ansible all -m shell -a "df -hP|awk 'NR>1 && int(\$5) > 30'"|awk '/success/{ip=$1;next}{print ip,$0}'
10.212.52.252 /dev/sda9 9.9G 2.9G 6.5G 31% /opt
10.212.52.252 /dev/sda6 5.0G 1.9G 2.8G 41% /tmp
10.212.52.252 /dev/sda5 9.9G 3.9G 5.5G 42% /usr
10.212.52.252
10.212.52.14 /dev/cciss/c0d0p5 9.9G 3.2G 6.3G 34% /usr
10.212.52.14
10.212.52.16 /dev/cciss/c0d0p7 9.9G 4.0G 5.4G 43% /tmp
10.212.52.16 /dev/cciss/c0d0p5 9.9G 2.9G 6.5G 31% /usrdf: `/root/.gvfs': Permission denied
10.212.52.16
上面的结果是我在自己的测试环境上执行的结果。可以看到多出的空行也打印了主机的IP 。还会需要注意的,我这里ansible输出的success是小写的。
不知道以上的问题是不是使用的环境不同造成的。我运行的环境是ansible主机为redhat6,ansible版本为1.9,被取数据主机有redhat6和suse11 。不过这都是小问题,同样可以通过处理获取到正常的结果。
上面的大牛的结果,我使用ansible api 执行,如下,可以对比下:
[root@localhost ~]# cat /tmp/test.py
#!/usr/bin/env python
# coding=utf-8
# author : www.361way.com
# mail : itybku@139.com
import ansible.runner
#import json
runner = ansible.runner.Runner(
module_name='shell',
module_args="df -hP|awk 'NR>1 && int($5)>30'",
pattern='all',
forks=10
)
results = runner.run()
#print results
for (hostname, result) in results['contacted'].items():
if not 'failed' in result:
for line in result['stdout'].split('\n'):
print "%s %s" % (hostname, line)
# 执行结果如下
[root@localhost ~]# python /tmp/test.py
10.212.52.16 /dev/cciss/c0d0p7 9.9G 4.0G 5.4G 43% /tmp
10.212.52.16 /dev/cciss/c0d0p5 9.9G 2.9G 6.5G 31% /usr
10.212.52.252 /dev/sda9 9.9G 2.9G 6.5G 31% /opt
10.212.52.252 /dev/sda6 5.0G 1.9G 2.8G 41% /tmp
10.212.52.252 /dev/sda5 9.9G 3.9G 5.5G 42% /usr
10.212.52.14 /dev/cciss/c0d0p5 9.9G 3.2G 6.3G 34% /usr
上面的方法中实际执行时,比我们预期需要的效果少了主机名一项。这里我换做执行脚本实现,实现效果如下:
#/bin/bash
# author : www.361way.com
IP=`ip add show|grep inet|grep 10|awk '{print $2}'`
df -hl|grep '^/'|sed 's/%//g'|awk '{if($5>30) print $0}'|while read line
do
echo $IP `hostname` $line
done
# 执行结果如下
# sh aa.sh
10.212.52.253/24 localhost /dev/sda3 9.5G 5.7G 3.4G 64 /
10.212.52.253/24 localhost /dev/sda2 39G 19G 18G 52 /home
10.212.52.253/24 localhost /dev/sda6 9.5G 7.1G 2.0G 78 /usr
使用ansible api 执行该脚本的结果如下:
# python dfscript.py df: `/root/.gvfs': Permission denied df: `/root/.gvfs': Permission denied 10.212.52.16/24 linux /dev/cciss/c0d0p7 9.9G 4.0G 5.4G 43 /tmp 10.212.52.16/24 linux /dev/cciss/c0d0p5 9.9G 2.9G 6.5G 31 /usr 10.212.52.252/24 zjhz-bmc-test /dev/sda9 9.9G 2.9G 6.5G 31 /opt 10.212.52.252/24 zjhz-bmc-test /dev/sda6 5.0G 1.9G 2.8G 41 /tmp 10.212.52.252/24 zjhz-bmc-test /dev/sda5 9.9G 3.9G 5.5G 42 /usr 10.212.52.14/24 linux /dev/cciss/c0d0p5 9.9G 3.2G 6.3G 34 /usr
dfscript.py脚本内容如下
# cat dfscript.py
#!/usr/bin/env python
# coding=utf-8
# author : www.361way.com
# mail : itybku@139.com
import ansible.runner
#import json
runner = ansible.runner.Runner(
module_name='script',
module_args="aa.sh",
pattern='all',
forks=10
)
results = runner.run()
#print results
for (hostname, result) in results['contacted'].items():
if not 'failed' in result:
for line in result['stdout'].split('\r\n'):
#print "%s %s" % (hostname, line)
print line
直接对该脚本执行后的结果进行grep 标准输出时,会发现其行与行之间是以\r\n这样的方式分行的。

所以在数据获取方面,尽量以ansible api 的方式进行获取,而api 的使用非常简单,无法是几个参数的替换后面再调用run方法,最终在对结果进行处理。而涉及多项信息获取时,建议使用自定义模块的方法,先将所需数据取回来,以json方式返回---ansible自定义模块所要求的格式。返回后可以再以api 或其他方式处理返回的数据即可。
以上就是ansible实战—磁盘使用率筛选的详细内容,更多请关注CTO智库其它相关文章!